- 01/20
- 2006
-
QQ扫一扫

-
Vision小助手
(CMVU)
电表读数和条形码识别系统的研究
赵宇 胡金麟 欧阳骏
(北京微视新纪元科技有限公司,北京 100083)
摘 要 电表读数和条形码识别系统弥补了人工读数和数据录入速度慢的不足,从而更快捷,更准确的解决了大量回收电表的读数统计问题。它首先使用了条形码识别方法对电表图象中的条形码进行识别,然后利用字符串识别方法对表中的数字进行识别,最后将识别结果以条形码作为索引和图象数据一起存入数据库,如果需要和已有数据库进行比较,则同样以条形码作为索引,将得到的电表读数同已有数据库中的数据进行比较,以确认正确读数。
关键词 条形码识别 字符串识别 图象增强 预处理
Abstract The Meter Reading and Barcode Recognition System makes up for the poor speed of manual reading and writing, and solves the reading statistical problem of large numbers of old meters more rapidly and more accurately. First, the system recognizes the barcode in the meter image by using the Barcode Reader, and then it recognizes the reading by using the String Reader, last, it saves all the results and the image into the database according to the barcode. The system can confirm the recognition result by comparing with the existing database.
Keywords barcode recognition, string recognition, image enhancement, preprocess
1、引 言
电表在达到报废年限后需要相关部门回收,回收后对报废表的读数进行记录,以确认该只电表的用电量。目前大量的回收电表的读数记录主要依靠人工来完成,从速度上和数据录入的准确性上都受到一定的限制。由于电表新产品的不断出现,以前使用的电表不断的达到报废年限,电表的大量回收和数据统计已经成为了一个很重要的工作。但是由于人工操作的特点导致了在电表读数统计上产生了很大的瓶颈,这就必须投入大量的人力物力来解决这一瓶颈。在这样的背景下,电表读数系统的自动化就显得尤为重要。
电表回收统计的现场环境对电表读数的识别有很大的影响。由于电表是从长期使用的地方拆卸下来,所以表面的污渍会很多,这也严重影响了电表读数的识别率。电表的大小尺寸规格都各不相同,这也给识别的工作带来了很大的影响。另外由于操作的问题或者电表在表箱中的偏移导致电表在摄像头中成像有一定的角度,这些有角度的数字和条形码对识别率也有一定的影响。
电表的表字一般来说有两种:一种是黑底白字的读数,一种是白底黑字的读数,这两个读数的识别是不尽相同的。由于白底黑字的周围通常是黑色的边框,这样使得白底很少,甚至有时黑字和黑色边框连成一体,这也导致白底黑字的识别率比通常字符识别率要低的多。
由于这些现场环境的影响使得目前的电表读数系统的识别率不高,一般只能达到60%甚至更低。一些技术性的问题如角度,黑字等无法克服也使得电表读数系统的开发很有限。并且多数的识别系统只是针对电表读数,而条形码要通过条码枪来完成,而电表的规格和角度的不确定,使得条码识别不能自动完成。所以目前的电表读数系统自动化的程度不是很高。
本系统正是在这样的应用背景下研发的。电表读数和条形码识别系统可以一次性识别0~360度的任意角度的条形码以及正负5度以内的白底黑字和黑底白字的数字。并且在表字和条形码完整的情况下识别率在85%以上。并且本系统已经成功应用于一些电表回收统计的领域,也取得的很好的效果。
2、系统概述
电表读数和条形码识别系统有两种方法:单表系统和表箱系统。前者是将电表单个的放在传送带上,通过外触发装置得到电表的位置,然后进行采图处理,将处理后的数据和图象一起存入数据库中。后者是将表箱放在传送带上通过摄像头的移动分别处理表箱中的表,处理完成一箱再进行下一箱处理。这两个系统各有优缺点,单表系统的优点是对于同一型号的电表图象的采集可以自动完成,并且摄像头可以固定不动。缺点是需要两个操作人员,一个人负责从表箱中将表放到传送带上,另一个人负责从传送带上移入表箱中。如果电表的规格不同,还需要一个人调整摄像头的高度。表箱系统的优点是不用从表箱中移出移入电表,缺点是需要移动摄像头到每个电表的位置。对于不同的应用场合和不同的系统要求,我们分别使用了以上两种系统。
本系统的硬件部分包括:一台Smart Camera摄像头,一个工业级的镜头,一个专用光源,一台测试计算机,一台服务器。
本系统所使用的摄像头是一款网络摄像头,由于它采用了内嵌式的系统,可以将所有的处理过程放在摄像头中进行,这样可以快速的完成识别工作,然后将识别结果和图象一起上传到数据库中保存。
本系统的软件部分包括一个识别处理软件和一个数据库管理软件。
3、条形码和读数的识别
3.1 光源的选择
电表的读数和条形码的识别会受到环境光的影响,由于电表的表面有一层玻璃罩子,所以不同方向来的光线可能会反射进入摄像头中导致成像时会产生一些亮点和亮线。所以我们要选择一个合适的光源来加强某些方向的光,同时减弱其他方向的自然光。光源的选择对于成像质量以及最终的识别结果都有很大的影响。图1显示了光源对图象质量的变化。

图1:光源对图象质量的影响
本系统采用的光源是CCS的二极管光源,它的光照比较均匀,由于摄像头从上向下拍摄,所以光源要与电表表面成一定的角度,这样会避免主光源进入到摄像头中。这里采用了侧面光的增强效果。从图象上可以看出选择本系统的光源对于成像质量有很大的提高。
3.2 图象预处理
由于现场复杂情况的影响,得到的电表图象表面总是会有很多污渍,电表读数和条形码也很模糊。所以要对得到的原始图象进行图象增强,去除一些噪声,得到一个相对清晰易于处理的图象。
本系统对原始图象进行如下变换:
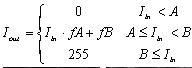
其中 ![]()
变换前后的图象如图2所示。

图2:变换前后条形码图象比较
3.3 条形码识别
条形码的识别对图象的分辨率有很大要求,为了保证条形码识别的准确性,条形码的图象要求无遮挡,这里无遮挡的意思就是沿着条形码的方向划一条线,保证该条线上任意一点都有数据值。目前常用的条形码编码器有:Codabar,Code39,Code93,Code128,Ean8,Ean13等。国内电表常用的条形码编码器主要是Code39和Code128,我们可以从这两种编码器入手进行识别。Code128是一种高密度字母数字条码,有106种不同的打印模式,Code39是比Code128简单的一种字母数字条码
条形码是以最细一条暗线或者明线的宽度作为最小编码单元。最小单元尺寸是以象素个数为单位的,由于图象大小的不同最小单元尺寸也会有所不同。最小单元确定以后,其他较厚的部分就按着连续几个最小单元进行编码。
图3 条形码结构
图3是一个code128码的例子,这个条形码的构成是这样的:前面是一部分平静区,这部分标志着搜索条形码的开始。挨着平静区的是起始区,不同的条码有不同的起始区,这部分是条码开始的标志,也是条码类型确定的标志。接下来是数据区,数据区的解码是按着编码表中的规则进行的。后面的校验区是条码数据按着某种规则计算出来的数据,它对条形码的识别起着重要的作用,如果校验位错误的话,将不产生识别结果。后面的部分是停止区,标志着条码的结束,不同的编码器有不同的停止区。最后要有一块平静区,标志条码搜索的结束。
上面提到的条码都是指一维条码,它的数据信息全部在同一个方向上,在它的垂直方向上是不包含信息的。条码具有一定的长度主要是给条码枪提供一个稳定的识别区域。
3.4 字符串识别
本系统所使用的字符串识别方法是在字符识别(OCR)的基础上进行的。它的识别过程如图4所示。
预处理的任务是从原始图象上搜索最佳的字符串行,可以根据字符的方向特性在图象上搜索。搜索到字符串的位置后,对字符串的水平竖直两个方向进行检测,得到字符串的大体方向,然后对字符串进行旋转,使其角度为0。由于电表表字的大小并不确定,所以需要将表字图象进行规一化。最后将图象二值化,存入数据库中。
经过预处理后的图象已经成为一个二值矩阵,其中表字为0,空白为1。字符分割算法就是通过矩阵中的0,1分布将字符串图象分割成字符图象。然后每一个字符图象都规一化成一个统一的矩阵,这里使用16×32的矩阵。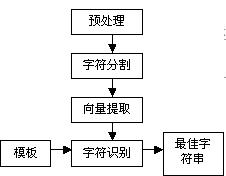
图4 字符串识别过程
接下来要做的是提取单个字符的特征向量,这些特征向量主要包括一些角点,弧线点,根据这些特征点可以将原始矩阵分成子矩阵。原始的特征向量为:
![]()
其中![]() 是竖直方向的中心,L是特征的长度,
是竖直方向的中心,L是特征的长度, ![]() 是特征角的余弦和正弦值,C是特征的曲率。
是特征角的余弦和正弦值,C是特征的曲率。
识别的过程就是按着下面的规则计算特征向量属于字符模板的概率:
![]()
取其中概率最大的字符作为识别的结果。
对于本系统来说,首要的任务是完成模板的学习,通过电表中出现的字体分别定义它的模板。根据模板的特性将模板分为白底黑字和黑底白字。如图5所示。

图5 模板的建立
由于同一块电表表字是同一类字体,根据这一特点,我们可以对字符串做一些限制,从而得到最佳的字符串。这些限制条件主要包括:
1.字符的长度范围
2.字符类型(即数字还是字母还是其他字符,本系统中使用的为数字字符)
3.字符串前景属性(前景黑色或者前景白色)
4.字符串接受度(即按着匹配度选择字符)
5.字符串角度范围
6.字符串尺度范围
7.字符串纵横比(即字符串的面率)的范围
3.5 系统处理过程
系统的处理过程是:
1.使用条形码识别模块从图象上搜索条形码并识别
2.使用字符串识别模块分别搜索和识别白底黑字和黑底白字的读数
3.以条形码作为索引从数据库中查找要比较的数据,提取数据进行比较
4.对于比较结果的不同对结果数据进行分类处理
5.以条形码作为索引对数据和图象进行保存
4、实验和结论
4.1 条形码
1.正常的条形码:
![]()
结果:KTT02Y2734302J44B
2.经过图象增强后可以处理的条形码:

结果:GE30068494402Q480
4.2 读数

结果:黑底白字:6726,分值:90.7,角度3.11,尺度0.914,纵横比1.015,首字符X-center:288.65,Y-center:557.87,最小字符分值:85.1,最大字符分值:96.4

结果:黑底白字:00937,分值:90.6,角度:359.6,尺度0.921,纵横比:0.990,首字符X-center:253.28,Y-center:560.25
白底黑字:018652,分值:83.3,角度:359.73,尺度0.769,纵横比:1.018,首字符X-center:253.28,Y-center:560.25
本系统的功能是将电表的读数和条形码一次性读出,根据条形码与现有数据库进行比较,然后保存当前图象和识别结果,它通过光源的选择和图象的预处理得到一个质量相对好的图象,然后使用了字符串识别和条形码识别两个模块进行处理。在图象无遮挡和分辨率允许的情况下,条形码的识别率可以达到90%以上,黑底白字的识别率为85%左右,白底黑字的识别率为75%以上。
下一步的工作是进一步完善白底黑字识别模块,将黑字周围黑底的影响降为最低。并且解决电表中的曲面表字。
参 考 文 献
1. “Matrox Imaging Library”, Matrox Electronic Systems Ltd. March 1, 2002.
2. La Manna S., Colla A.M., and Sperduti A., “Optical Font Recognition for Multi-Font OCR and Document Processing”, 10th International Workshop on Database and Expert Systems Applications, 1-3 September, 1999, Firenze. pp. 549-553. IEEE Press.
3. .A. Zramdini, “Study of optical font recognition based on global typographical features”, PhD thesis, University of Fribourg, 1995
4. E. Kavallieratos, N. Antoniadis, N. Fakotakis, G. Kokkinakis, “Extraction and Recognition of Handwritten Alphanumeric Characters from Application forms”, DSP97, pp.695-698, 1997
版权所有,任何单位和个人都不得以任何形式转载,谢谢!